Note: This tutorial was originally written as an Jupyter Notebook (ipynb). If you would like to run or edit the notebook, it can be found here
The example dataset used in this tutorial contains 2D immunofluorescence images of the Drosophila intestine obtained using a spinning-disc confocal microscope. The dataset is describes a "MARCM" experiment from the following paper.
MARCM is a genetic technique whereby mitotic recombination generates GFP-marked homozygous mutant cells from heterozygous precursors. Over time, individually marked cells divide adjacent to each other and create "clones" of mutant cells, surrounded by unmarked wild-type cells:
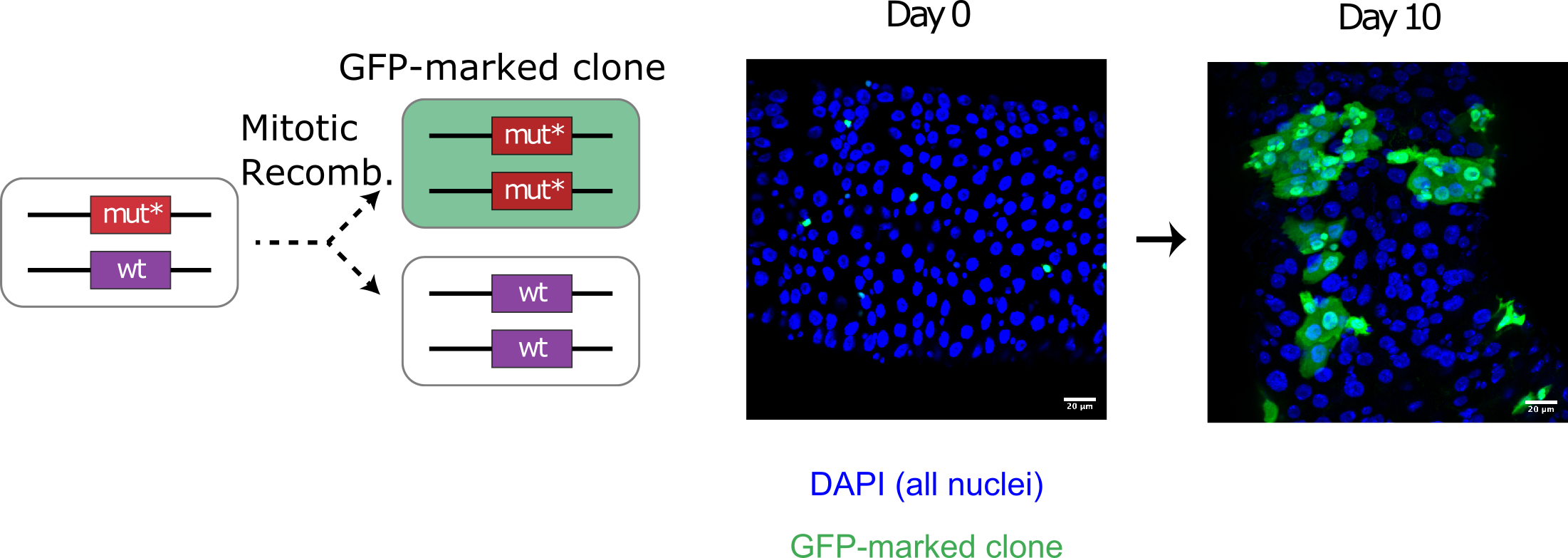
Left:Genetic labelling by MARCM. Right: Labelled cells grow over time into 'clones'.
In this dataset, intestines were imaged using four channels:
- C0 : DAPI (nuclear marker)
- C1 : GFP (clone marker)
- C2 : PDM1 staining (EnteroCyte marker)
- C3 : Prospero staining (EndoEndocrine marker)
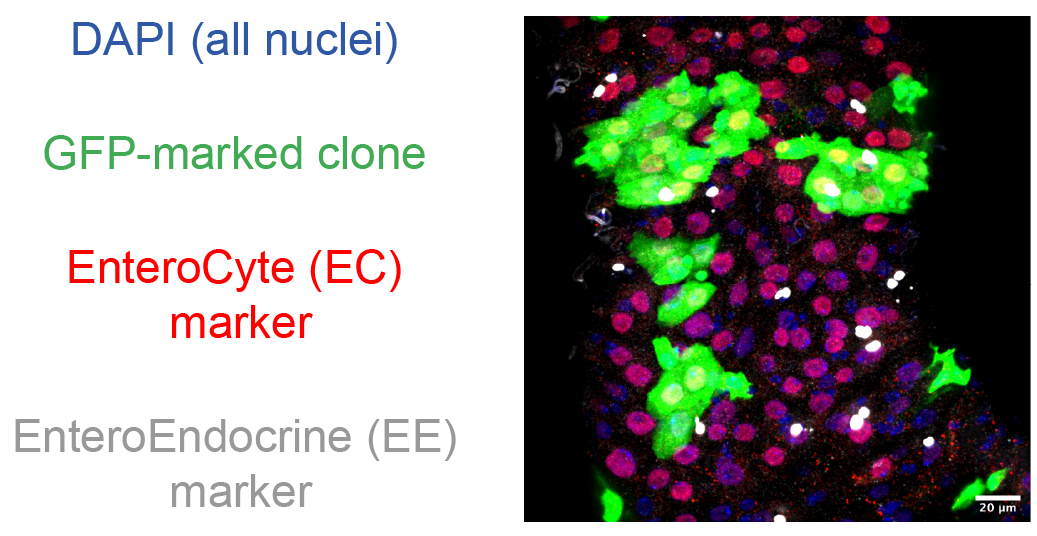
composite image
We aim to investigate:
1) Does gene of interest regulate cell proliferation?
2) Does our gene of interest control cell differentiation?
3) Does gene of interest effect local tissue cell arrangement and structure?
To address each of these aims we will:
- Quantify the number and type of cells present in each image.
- Classify whether each cell resides outside or inside a clone.
- Calculate the number of neighbours each cell has and what type of cell each of those neighbours are.
These data will help us address of experimental aims since:
- We can measure if our gene of interest regulates cell proliferation by comparing the number of cells per mutant clone, to the number of cells per control clone i.e. clones generated in wild-type animals lacking any mutation.
- We can determine if our gene of interest regulates cell differentiation by comparing the percentage of each cell type inside vs. outside a clone (since only cells inside a clone are mutant for our gene of interest).
- We can determine whether our mutation of interest affects local tissue cell arrangement and structure by comparing the number and type of cell neighbours inside vs outside a clone.
Most functions in clonedetective are parallelised using Dask. When using the Dask distributed scheduler, we can access an interactive dashboard that details our computations' status, progress, and history. While especially useful when working on a remote cluster, the interactive dashboard is a great addition even when working locally (e.g. MacBook).
For example, here is what the dashboard looks like when measuring cell properties using the CloneCounter.make_measurements()) call described below. Each line of the 'Task Stream' corresponds to one of 8 logical cores on my MacBook Pro.

example Dask dashboard
N.B. Initiating a Dask scheduler is optional when working on your local machine. If you don't launch one, all computations will still run; you just won't have access to the fancy dashboard!
Launch the scheduler as follows on your local machine and click on the dashboard link:
from dask.distributed import Client
c = Client()
c

If you're working on a remote cluster, e.g. a SLURM HPC, please see the relevant Dask guides.
Import and instantiate CloneCounter subclass
The LazyCloneCounter subclass uses Dask to lazy load image series that may be too large to fit in RAM. If your data is small enough to fit into RAM, you can speed things up using the PersistentCloneCounter subclass.
For more details, see the advanced tutorial (coming soon).
from clonedetective.clone_counters import LazyCloneCounter
We intialise a LazyCloneCounter with four required arguments:
- exp_name : str -> name of the experiment
- img_name_regex : str -> regular expression used to extract unique identifies from image filenames
- pixel_size : str -> pixel size in $\mu m^{2}$
- tot_seg_ch : str -> image channel used to define the total number of cells e.g. DAPI channel.
In this experiment, images using the following pattern:
- 'a1' if from a wild-type animal. 'a2' if from a mutant animal.
- 'g01' for gut 1. 'g02' for gut 2 etc.
- 'p1' for position 1. 'p2' for position 2 etc.
Image names such as 'a1g01p1' can thus be parsed using the regular expression "a\dg\d\dp\d".
exp = LazyCloneCounter(
exp_name="Marcm2a_E7F1",
img_name_regex=r"a\dg\d\dp\d",
pixel_size=0.275,
tot_seg_ch="C0",
)
We add images to the LazyCloneCounter instance by passing a filename "glob" for each of the image channel. For example, the directory "data/MARCM_experiment/images/C0/" contains a series of tif images for the C0 channel:
import os
# show the first 5 files in the directory
os.listdir("data/MARCM_experiment/images/C0/")[:5]
In this experiment, tifs for each image channel (C0, C1, C2 and C3) are stored in four separate folders.
exp.add_images(
C0="data/MARCM_experiment/images/C0/*.tif",
C1="data/MARCM_experiment/images/C1/*.tif",
C2="data/MARCM_experiment/images/C2/*.tif",
C3="data/MARCM_experiment/images/C3/*.tif",
)
Our image data is stored in a Xarray DataSet, which is a collection of Xarray DataArrays, each containing Numpy or dask arrays with explicitly labelled dimensions and coordinates:
exp.image_data
As an example of how these work, the coordinates of the "img_name" dimension are the individual image names, while the coordinates of "y" and "x" dimensions correspond to image size in $\mu m^{2}$:
exp.image_data["img_name"]
To access specific images, we can use the convenient .sel notation. Here, we index an image, load it into RAM (the .compute() call), and display it using matplotlib.
import matplotlib.pyplot as plt
# display the DAPI channel for the first image
ax = plt.subplots()[1]
ax.imshow(
exp.image_data["images"].sel(img_channels="C0", img_name="a1g01p1").compute(),
cmap="gray",
vmax=12000,
)
ax.set_title("DAPI channel for img_name: a1g01p1")
ax.set_axis_off()

We can add segmentations in the same fashion...
TIP. At a minimum, clonedetective requires a segmentation for the "tot_seg_ch" (see above for definition). If you do not have a suitable segmentation, check out the example tutorial using StarDist.
exp.add_segmentations(C0="data/MARCM_experiment/segmentations/C0_stardist_segs/*.tif")
Segmentations have now been added to the Xarray dataset:
exp.image_data
Similarly, we can access specific segmentations using the .sel notation:
from clonedetective.utils import generate_random_cmap
# display total segmentation for the first image
ax = plt.subplots()[1]
ax.imshow(
exp.image_data["segmentations"]
.sel(seg_channels="C0", img_name="a1g01p1")
.compute(),
cmap=generate_random_cmap(),
interpolation="none",
)
ax.set_title("Total segmentation for img_name: a1g01p1")
ax.set_axis_off()

We next need to measure properties of each segmented cell (label) within our images:
exp.make_measurements()
Without providing an arguments, CloneCounter.make_measurements()) defaults to pairing the 'tot_seg_ch' segmentation channel to each of the image channels.
The segmentation-image channel pairs used for cell measurements can be accessed via the CloneCounter.seg_img_channel_pairs attribute.
exp.seg_img_channel_pairs
TIP: If these segmentation-image channel pairs are unsuitable for your experiment, they can be customised as detailed in the advanced tutorial (coming soon).
TIP:
As a default,CloneCounter.make_measurements()) calculates every cell's mean intensity, centroid, and area. If we require additional measurements, we can supply the extra_properties with a list containing any 'regionprops' metrics from the scikit-image measure module. For example, we can additionally calculate 'eccentricity' as follows:
exp.make_measurements(extra_properties=["eccentricity"])
The primary result from the CloneCounter.make_measurements()) call is a CloneCounter.results_measurements attribute. This is a pandas DataFrame containing all per cell measurements.
exp.results_measurements
We now aim to determine whether each cell resides inside or outside a "clone". To do this, we first define a 'threshold' that categorises whether a cell is GFP positive or negative. This can be as simple as "mean_intensity > 1000", or involve multiple conditions e.g. "mean_intensity > 1000 & eccentricity > 0.3".
Thresholds are not applied directly to the C1 (GFP) image. Instead, for every label of the total segmentation channel (in this case C0: DAPI), we look at its corresponding intensity in the C1 (GFP) channel. We do this by querying the CloneCounter.results_measurement dataframe and keeping only those labels that meet our desired threshold criteria.
The CloneCounter class provides a helper method testing_possible_thresholds that can plot and compare different thresholds:
exp.testing_possible_thresholds(
int_img="a1g10p1",
thresholds=[
['int_img_ch == "C1" & seg_ch == "C0" & mean_intensity > 0'],
['int_img_ch == "C1" & seg_ch == "C0" & mean_intensity > 100'],
['int_img_ch == "C1" & seg_ch == "C0" & mean_intensity > 1000'],
['int_img_ch == "C1" & seg_ch == "C0" & mean_intensity > 10000'],
],
figure_size=(8, 7),
interpolation="none",
)

From this test, we can see that a mean intensity threshold of 1000 appears roughly suitable, as its binary image on the left keeps most of the GFP positive cells, while excluding GFP negative cells.
If we were still unhappy with this as a simple threshold, we could increase stringency by adding another threshold on a different cell measurement. Below, we keep a mean intensity threshold constant at 1000, while varying an additional eccentricity threshold:
exp.testing_possible_thresholds(
int_img="a1g10p1",
thresholds=[
[
'int_img_ch == "C1" & seg_ch == "C0" & mean_intensity > 1000 & eccentricity > 0'
],
[
'int_img_ch == "C1" & seg_ch == "C0" & mean_intensity > 1000 & eccentricity > 0.3'
],
[
'int_img_ch == "C1" & seg_ch == "C0" & mean_intensity > 1000 & eccentricity > 0.6'
],
],
figure_size=(8, 8),
interpolation="none",
)

In this example, most cells are pretty round and so both eccentricity == 0 and eccentricity == 0.3 look suitable.
Once we have decided on a threshold, we can plug it into the CloneCounter.add_clones_and_neighbouring_labels method and apply it to all images:
exp.add_clones_and_neighbouring_labels(
thresholds=[
'int_img_ch == "C1" & seg_ch == "C0" & eccentricity > 0.3 & mean_intensity > 1000'
],
thresh_name="GFP",
calc_clones=True,
)
This method call does a couple of things:
1) It updates CloneCounter.results_measurements with an additional boolean column describing whether a cell (label) is positive or negative for the desired threshold.
exp.results_measurements.head()
2) It adds new neighbourhood count and clone images to CloneCounter.image_data. (See the additional 'C1' data variable in the Xarray dataset below)
exp.image_data
To illustrate what these new images are, lets plot and walkthrough them for one img_name (e.g. "a1g01p1"). As all these new images derive from the original total segmentation image, we will plot this, along with the original fluorescent image (channels C0 and C1).
We first import helper plotting functions from clonedetective.utils:
from clonedetective.utils import RGB_image_from_CYX_img, plot_new_images
import numpy as np
# grab one img_name from dataset
img = exp.image_data.sel(img_name="a1g01p1")
fluo_img = img["images"].data.compute()
# create RGB image of DAPI and GFP channels
RGB_image = RGB_image_from_CYX_img(
red=None, green=fluo_img[1, ...], blue=fluo_img[0, ...]
)
# create a list of RGB fluorescent, total segmentation and the new images for easy plotting
img_to_plot = np.concatenate(
[img["segmentations"].data.compute(), img["GFP"].data.compute()]
)
img_to_plot = [RGB_image] + [img for img in img_to_plot]
# create text labels for our plot
text_labels = ["DAPI + GFP", "total_segmentation"] + img["GFP"].coords[
"GFP_neighbours"
].values.tolist()
plot_new_images(
img_to_plot[:6],
text_labels[:6],
"ABCDEF",
figure_shape=(2, 3),
figure_size=(8, 6),
vmax=np.unique(img_to_plot[1]).shape[0],
interpolation="none",
)

(A) - two channel fluorescent image
(B) - total segmentation image i.e. from exp.image_data['segmentations'].
(C) - labels of total segmentation image have been extended so they touch each other.
(D) - labels that did not meet our threshold (C1_neg_labels).
(E) - labels that did meet our threshold (C1_pos_labels).
(F) - touching labels that did meet our threshold have been merged into 'clones'
plot_new_images(
[img_to_plot[0]] + img_to_plot[6:],
[text_labels[0]] + text_labels[6:],
"AGHI",
figure_shape=(1, 4),
vmax=np.unique(img_to_plot[6]).shape[0],
colorbar=True,
label_cmap="magma",
)


(G) - Parametric image where the number of total neighbours is mapped to color.
(H) - Parametric image where the number of C1neg neighbours is mapped to color.
(I) - Parametric image where the number of C1pos neighbours is mapped to color.
As well as a GFP channel, our dataset contains fluorescence channels for PDM1 (channel C2) and Prospero (channel C3) immunostains. Since PDM1 marks EnteroCyte (EE) cells, and Prospero marks EnteroEndocrine (EE) cells, we can use thresholds to define these cell types within our images.
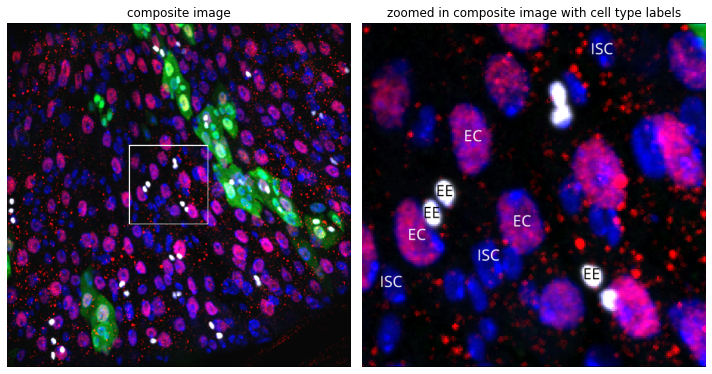
Cropped image of intestine stained with DAPI, GFP, PDM1 and Prospero with labelled cell types
First, we define a threshold for EC cells. Since EC are large absorptive cells, we can use total intensity rather than mean intensity for thresholding:
exp.results_measurements = exp.results_measurements.eval(
"total_intensity = mean_intensity * area"
)
To find suitable PDM1 (C2) threshold, we can again use the CloneCounter.testing_possible_thresholds()) method:
exp.testing_possible_thresholds(
int_img="a1g01p1",
thresholds=[
['int_img_ch == "C2" & seg_ch == "C0" & total_intensity > 5e3'],
['int_img_ch == "C2" & seg_ch == "C0" & total_intensity > 5e4'],
['int_img_ch == "C2" & seg_ch == "C0" & total_intensity > 5e5'],
['int_img_ch == "C2" & seg_ch == "C0" & total_intensity > 5e6'],
],
figure_size=(8, 7),
interpolation="none",
)

So 'total_intensity > 5e5' works well for the PDM1 (C2) channel.
Next, let's find a suitable Prospero threshold to define EE cells:
exp.testing_possible_thresholds(
int_img="a1g10p1",
thresholds=[
['int_img_ch == "C3" & seg_ch == "C0" & mean_intensity > 100',],
['int_img_ch == "C3" & seg_ch == "C0" & mean_intensity > 1000',],
['int_img_ch == "C3" & seg_ch == "C0" & mean_intensity > 5000',],
['int_img_ch == "C3" & seg_ch == "C0" & mean_intensity > 25000',],
],
figure_size=(8, 7),
interpolation="none",
)

'mean_intensity > 1000' looks to work well for the Prospero (C3 channel).
IMP -> However, it is crucial that threshold definitions for cell types are mutually exclusive i.e. a cell cannot be both EC_pos and EE_pos. If thresholds are not mutually exclusive, the same cell might be counted more than once when we later calculate percentage cell types and the number of neighbours.
At the moment, our thresholds are not mutually exclusive since there might a small percentage of cells that have PDM1 'total_intensity > 5e5' and Prospero 'mean_intensity' > 1000. We can check this using the CloneCounter.mutually_exclusive_cell_types()) method after defining out initial cell type thresholds:
exp.add_clones_and_neighbouring_labels(
thresholds=['int_img_ch == "C2" & seg_ch == "C0" & total_intensity > 5e5',],
thresh_name="EC",
calc_clones=False,
)
exp.add_clones_and_neighbouring_labels(
thresholds=['int_img_ch == "C3" & seg_ch == "C0" & mean_intensity > 1000',],
thresh_name="EE",
calc_clones=False,
)
exp.mutually_exclusive_cell_types()
To avoid this problem, we can define an additional double positive cell type (ECEC), and more precisely define our cell types as:
- EC cells : positive for PDM1 (channel C2), negative for Prospero (channel C3).
- EE cells : negative for PDM1 (channel C2), positive for Prospero (channel C3).
- ECEE cells : positive for PDM1 (channel C2), positive for Prospero (channel C3)
exp.add_clones_and_neighbouring_labels(
thresholds=[
'int_img_ch == "C2" & seg_ch == "C0" & total_intensity > 5e5',
'int_img_ch == "C3" & seg_ch == "C0" & mean_intensity < 1000',
],
thresh_name="EC",
calc_clones=False,
)
exp.add_clones_and_neighbouring_labels(
thresholds=[
'int_img_ch == "C2" & seg_ch == "C0" & total_intensity < 5e5',
'int_img_ch == "C3" & seg_ch == "C0" & mean_intensity > 1000',
],
thresh_name="EE",
calc_clones=False,
)
exp.add_clones_and_neighbouring_labels(
thresholds=[
'int_img_ch == "C2" & seg_ch == "C0" & total_intensity > 5e5',
'int_img_ch == "C3" & seg_ch == "C0" & mean_intensity > 1000',
],
thresh_name="ECEE",
calc_clones=False,
)
Now check again:
exp.mutually_exclusive_cell_types()
The final major cell type within the fly intestine are progenitor cells including Intestinal Stem Cells (ISCs) and EnteroBlasts (EBs). These can be defined as having small nuclei and not being 'EC_pos', 'EE_pos' nor 'ECEC_pos':
exp.add_clones_and_neighbouring_labels(
thresholds=["area_um2 < 50 & not EC_pos & not EE_pos & not ECEE_pos"],
thresh_name="ISCorEB",
calc_clones=False,
)
IMP -> However, as well as being mutally exclusive, our cell type thresholds also need to completely categorise every cell. At the moment, this is not the case, since large nuclei cells that are not 'EC_pos', 'EE_pos' nor 'ECEC_pos', have not been classified.
We can check using the following method:
exp.complete_set_of_cell_types()
We, therefore, define a threshold for a rare preEC cell type, which have large nuclei but are not 'EC_pos', 'EE_pos' nor 'ECEC_pos'.
exp.add_clones_and_neighbouring_labels(
# could also be defined as ["not EC_pos & not EE_pos & not ECEE_pos & not ISCorEB_pos"]
thresholds=["area_um2 > 50 & not EC_pos & not EE_pos & not ECEE_pos"],
thresh_name="preEC",
calc_clones=False,
)
This completes our cell type thresholding:
exp.mutually_exclusive_cell_types(), exp.complete_set_of_cell_types()
We now quantify numbers of clones and touching neighbours.
exp.measure_all_clones_and_neighbouring_labels()
This operation populates a CloneCounter.results_clones_and_neighbour_counts dictionary attribute with pandas dataframes for each defined cell type or clone threshold:
exp.results_clones_and_neighbour_counts.keys()
Each dataframe contains neighbour count information for that cell type e.g.
exp.results_clones_and_neighbour_counts["GFP"].head()
Next, we combine these dataframes together, along with the original CloneCounter.results_measurements dataframe, to return a final dataframe that contains information on all cell properties (e.g. mean_intensity), whether a cell inside a clone, and the number and type of neighbours a cell has:
df = exp.combine_neighbour_counts_and_measurements()
We can now export this DataFrame for future downstream analysis using your favourite data wrangling and plotting tools.
df.to_csv("data/example_results.csv", index=False)
To follow on with these analyses, please see tutorials: